本文最后更新于227 天前,其中的信息可能已经过时,如有错误请发送邮件到PZ_0828@163.com
MySQL 分库分表(水平拆分)后,全局唯一且趋势递增的主键ID的设计是一个核心挑战。不能再使用单个数据库表的自增ID(AUTO INCREMENT),因为它只能在单个数据库的单个表内保证唯一和递增。分库分表环境下需要全局唯一 ID。
数据库分表后,主键ID的处理是分布式系统的核心挑战之一。
分表后ID核心要求
| 特性 | 说明 | 重要性 |
|---|---|---|
| 全局唯一 | 整个分布式系统绝对唯一,不能出现重复 | ⭐⭐⭐⭐⭐ |
| 趋势递增 | 利于索引性能及排序 | ⭐⭐⭐⭐ |
| 高可用 | ID生成服务必须容错 | ⭐⭐⭐⭐⭐ |
| 低延迟/高性能 | 生成速度不影响业务吞吐 | ⭐⭐⭐⭐ |
| 易扩展 | 支持分表数量动态扩容,能够应对业务增长压力 | ⭐⭐⭐ |
主流ID生成方案详解
UUID
-- 生成示例:550e8400-e29b-41d4-a716-446655440000<br>SELECT UUID();- 原理:基于时间、网卡 MAC 地址、随机数等生成一个(通常表示为32位16进制数)的全局唯一标识符。
- 优点:实现简单(几乎所有语言都有内置库)本地生成,无网络开销,性能极高。全球唯一性保证非常好。
- 缺点:
- 完全随机无序:无序性导致索引碎片(B+树分裂),插入数据库时会导致严重的页分裂和索引碎片,极大影响写入性能(特别是 InnoDB 的聚集索引特性)。这是其最大缺点,通常不推荐用作数据库主键。
- 存储空间大:长度过长(128 位/32 字符),作为主键存储空间大,索引效率低。
- 可读性差
- 适用:小型临时系统,对存储和性能要求不高,且需要强唯一性的非核心业务;或用作关联其他系统的唯一标识(如 Session ID,文件 ID)
数据库自增ID
集中分配:
- 原理:单独建立一个数据库(或一个数据库中的一张表),专门用于生成 ID。该表使用 AUTO INCREMENT 功能。
- 优点:简单容易实现, 每次业务系统需要ID 时,向该表插入一条空记录,获取返回的自增 ID。
- 缺点:性能差,不推荐。
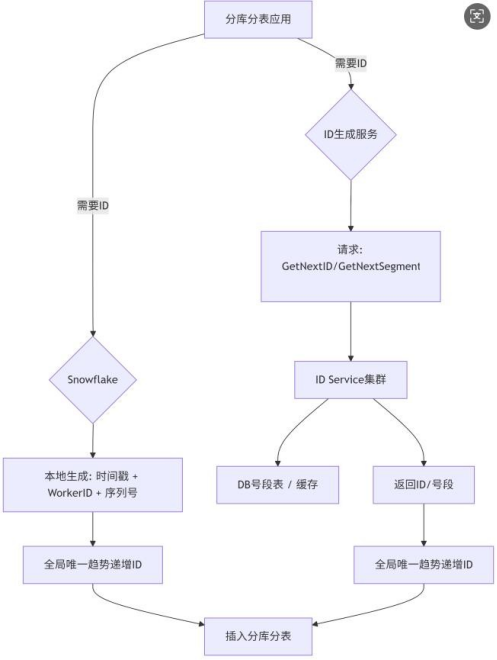
号段模式(Segment):常用且推荐的方式
- 原理:业务系统启动时或 ID 用完时,向中心数据库批量申请一个号段(例如:1000~2000)。中心数据库更新最大值(当前最大值 + 步长,如 1000+1000=2000),并返回号段范围(1000~2000)。业务系统在本地内存中使用这个号段(1000,1001,1002…… 2000)分配完后再去申请新号段。
- 优点:
- 生成的 ID 是数字,长度可控。
- 趋势递增(号段内连续,号段间递增)
- 性能较高(批量获取,减少数据库交互)
- 易于扩展(可部署多个中心数据库实例,通过设置不同初始值和相同步长来避免冲突,如:DB1初始1步长 1000, DB2 初始 2 步长 1000)。
- 缺点:
- 重启服务器可能会导致内存号段丢失
- 中心数据库是潜在的单点故障(需要高可用部署:主从、集群)
- 仍然依赖数据库,数据库性能可能成为瓶颈(虽然号段模式大大缓解)
- 号段用完时,请求新号段会有轻微延迟
Redis原子自增
# Python示例<br>import redis<br>r = redis.Redis()<br>def next_id(shard_id):<br> key = f"user_id:{shard_id}"<br> return r.incr(key) # 原子操作- 原理:利用Redis的
INCR/INCRBY命令原子性来生成自增 ID。 - 实现方式:
- 简单
INCR:INCR global id key。性能优于数据库简单获取,但仍需每次请求 - 号段模式:类似数据库号段模式。使用
INCRBY global_id_key step一次性获取一个号段范围,然后在本地内存消费。
- 简单
- 优点:
- 性能极高(
Redis内存操作) - 生成的 ID 是数字,长度可控
- 趋势递增
- 性能极高(
- 缺点:
- 数据持久化问题:Redis宕机可能导致号段丢失(即使有
AOF/RDB恢复点可能不是最新状态)。需要仔细配置持久化策略,存在丢失一小部分 ID 的风险。这是最大缺点 - 运维复杂度高
- 需要解决
Redis单点/集群问题(高可用部署)
- 数据持久化问题:Redis宕机可能导致号段丢失(即使有
- 适用:缓存层完备的高并发系统
Snowflake算法(主流方案)
// Java实现核心逻辑<br>long generateId() {<br> long timestamp = System.currentTimeMillis() - START_TIME;<br> return (timestamp << TIMESTAMP_SHIFT) |<br> (dataCenterId << DATACENTER_SHIFT) |<br> (machineId << MACHINE_SHIFT) |<br> (sequence++ & MAX_SEQUENCE);<br>}- 原理:通过算法生成一个64位的Long型ID。
- 优点:
- 高性能(单机每秒26万+)
- 趋势递增
- 无中心化依赖
- 缺点:
- 时钟回拨问题: 这是最大挑战。如果服务器系统时间发生回退(如
NTP同步),可能导致生成重复ID - 依赖机器配置:需要为每台部署
IDI生成服务的机器配置唯一的WorkerlD/DatacenterlD(可通过Zookeeper、Consul、数据库等协调服务分配) - 强依赖机器时钟:时钟不准或跳跃会影响单调递增性
- 时钟回拨问题: 这是最大挑战。如果服务器系统时间发生回退(如
- 改进方案:
- 关闭
NTP同步(不推荐,时间会漂移) - 运行时检测到时钟回拨则等待或报错(影响可用性)
- 扩展
WorkerlD位数,预留一部分 ID 作为“时间回拨缓冲”(如美团Leaf-Snowflake)
- 关闭
- 变种:
- 百度 (
UidGenerator) : 基于Snowflake, 采用数据库分配WorkerID,优化时钟处理 - 美团 (Leaf):
Leaf-Snowflake: 解决时钟回拨(使用Zookeeper顺序节点持久化时间戳)Leaf-Segment: 基于数据库号段模式的优化(双 Buffer 预加载)
- 滴滴 (
Tinyid): 纯基于数据库号段模式的服务化组件。
- 百度 (
选取规则
- 首选
Snowflake其工业级变种(Leaf-Snowflake,UidGenerator):性能最高、对数据库友好、无外部存储强依赖(除WorkerID配置)。需重点解决时钟回拨问题。适合追求高性能、低延迟的场景。 - 次选号段模式 (DB 或 Redis):实现相对简单,性能较好。DB 号段更成熟可靠,Redis 号段需警惕持久化风险。适合中等规模、对时钟问题敏感或已有可靠 KV 存储的场景。
Leaf-Segment/Tinyid是很好的服务化封装。 - ID生成服务:适合大型公司或复杂架构,需要统一管理 ID 生成,屏蔽底层细节。底层通常还是基于 Snowflake 或号段。
- UUID:仅适用于对存储和性能要求极低、且对顺序无要求的场景。
- DB 简单自增:绝对避免。
雪花算法 VS 号段服务

评论